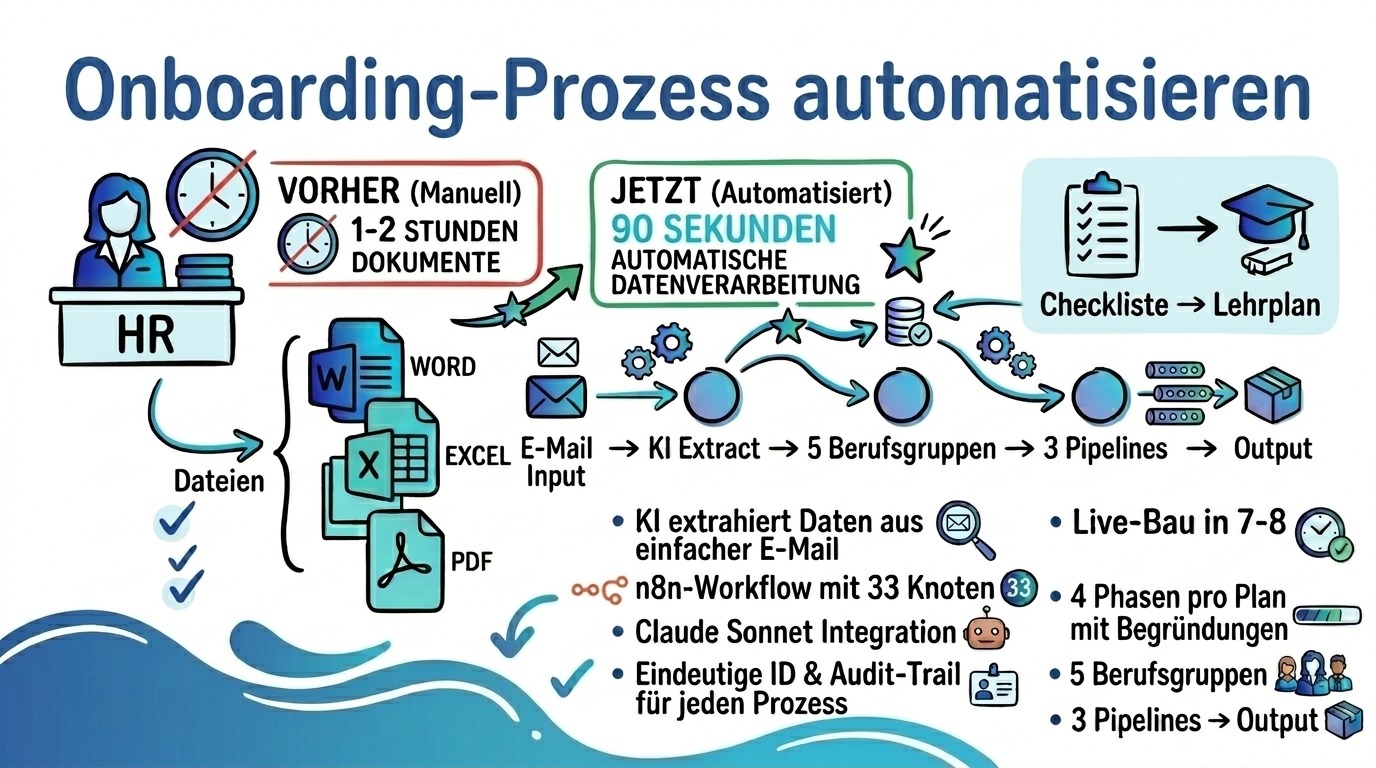
Wer den Onboarding-Prozess automatisieren will, hat in den meisten Genossenschaften der Wohnungswirtschaft kein Tool-Problem, sondern ein Zeitproblem. HR-Mitarbeitende schreiben heute zwischen einer und zwei Stunden an einem einzelnen Einarbeitungsplan. Den fertigen Plan liest später allerdings kaum jemand zu Ende.
Beim Open Space der Wohnungswirtschaft 2026 habe ich in sieben bis acht Stunden Live-Bauzeit gezeigt, wie das anders geht. Der Use Case wurde dabei am Montagmittag per Live-Voting unter drei Vorschlägen ausgewählt. Am Dienstag um 13 Uhr stand das Ergebnis im Plenum: drei Test-Mails, drei fertige Onboarding-Pläne, jeweils unter 90 Sekunden Bearbeitungszeit.
Hier kommt die ganze Story. Zudem die sechs Stolpersteine, die mich am Montagabend nochmal an den Schreibtisch gezwungen haben.
Warum der Onboarding-Prozess in der Wohnungswirtschaft automatisiert gehört
Eine Hausverwalterin fängt am Montag an. Wer schreibt heute also den Einarbeitungsplan? In den meisten Genossenschaften ist das nach wie vor HR. Daher kostet jeder neue Plan zwischen 60 und 120 Minuten reine Schreibzeit. Bei fünf Neueinstellungen pro Quartal sind das zwei Arbeitstage. Pro Quartal. Nur fürs Aufschreiben.
Insgesamt fließt damit viel HR-Zeit in Dokumente, die nach der ersten Woche kaum noch jemand öffnet. Außerdem entsteht ein Qualitätsproblem: Jeder Plan sieht anders aus. Compliance-Punkte fehlen mal hier, mal dort. Manche Pläne enthalten Begründungen für Aufgaben, andere nur Stichpunkte. Insbesondere die Frage „warum gehört das zur Einarbeitung“ bleibt oft offen, denn unter Zeitdruck schreibt niemand zwei Sätze pro Aufgabe dazu.
Genau das macht das Onboarding-Prozess automatisieren so reizvoll. Die Aufgabe ist klar umrissen, die Ausgangsdaten kommen aus einer einzigen Quelle (HR), und der Output ist drei Dokumente mit konsistentem Aufbau. Das ist ein Lehrbuch-Use-Case für eine KI-gestützte Pipeline.
Solche Live-Bau-Sessions möchte ich künftig öfter aufsetzen, gerade in Open-Space-Formaten. Genau dort entsteht die Energie, die ich dieses Mal erlebt habe: wenn Teilnehmende sehen, wie ein Prototyp in den Pausen wächst, wird aus „könnte man irgendwann mal“ ein „schaut, das läuft schon“.
Der Use Case beim Open Space: was am Dienstag im Plenum lief
Drei Vorschläge waren am Montagmittag zur Abstimmung gestellt. Gewonnen hat der Use Case, von dem ich beim Briefing am wenigsten Ahnung hatte: ein automatischer Onboarding-Plan-Generator für die fünf Berufsgruppen der Wohnungswirtschaft. Konkret: Führungskraft, Sachbearbeiter, Hausverwalter, Immobilienkaufmann sowie Techniker. Jede Gruppe mit eigenen Schwerpunkten von Stakeholder-Mapping bis hin zum Notdienst-Pool.
Das Bedienkonzept ist bewusst einfach gehalten. HR schickt eine ganz normale E-Mail an eine geteilte Mailbox. Kein Formular, kein Login, keine Pflichtfelder im klassischen Sinn. Innerhalb von 90 Sekunden kommen drei Dokumente zurück:
- Word für die HR-Akte
- Excel zum Filtern und Abhaken für den Vorgesetzten
- PDF zum Ausdrucken für den neuen Mitarbeiter
Jeder Plan deckt vier Phasen ab: Tag 1, Woche 1, Monat 1, Monat 3. Dabei hat jede Phase ein klares Ziel. Pro Aufgabe vier bis acht Punkte mit ein bis zwei Sätzen Begründung. Vor allem die Begründungen sind der Teil, auf den ich am stolzesten bin. Aus einer Checkliste wird so ein Lehrplan. Außerdem schafft das Vertrauen: Der neue Kollege weiß, warum er am Tag 1 in der Sicherheitsunterweisung sitzt.
Falls die HR-Mail unvollständig ist, fragt das System zudem höflich nach. Mit einer eindeutigen Vorgangs-ID im Betreff. Bis zu drei Iterationen. Erst wenn alle Pflichtfelder vorliegen, läuft die Plan-Generierung an. Dementsprechend gibt es keinen Sackgassen-Fall, in dem HR im Stress aufgibt.
So sieht das System unter der Haube aus
Unter der Haube läuft ein n8n-Workflow mit 33 Knoten. Er lauscht via Outlook-Trigger auf eine Shared Mailbox bei Microsoft 365. Eingehende Mails landen zunächst in einem Code-Node, der die wichtigsten Daten vorab extrahiert. Anschließend übernimmt Claude Sonnet das semantische Verständnis: Wer ist die neue Person, in welcher Rolle, ab welchem Datum, in welcher Abteilung, mit welcher Vorgesetzten?
Die KI mappt die Rolle auf eine der fünf Berufsgruppen und entscheidet, ob die Pflichtangaben vollständig sind. Falls etwas fehlt, generiert sie eine höfliche Rückfrage mit Vorgangs-ID. Dieser Teil ist der Rückfragen-Loop, der bis zu drei Mal greifen darf. Folglich entsteht keine Sackgasse, wenn HR im Stress eine Information vergisst.
Liegt der Vorgang vollständig vor, schaltet ein Switch-Node auf die Plan-Generierung um. Drei Generator-Pipelines laufen parallel: docx erzeugt das Word-Dokument für die HR-Akte, exceljs baut die filterbare Excel-Tabelle für den Vorgesetzten, pdfmake rendert das druckfertige PDF für den neuen Mitarbeiter, dazu kommt eine gemeinsame Renderschicht. Alle drei Pipelines teilen sich gemeinsame Design-Tokens. Daher sehen Header, Footer, Phasen-Tabelle und Begründungs-Spalte in jedem Format identisch aus.
Jeder Vorgang bekommt eine eindeutige ID nach dem Schema ONB-2026-0XX. Alle Schritte werden in einer n8n-Datenbank protokolliert. Monate später lässt sich nachvollziehen, wer wann was angefordert hat. Insbesondere für DSGVO-Audits in der Wohnungswirtschaft zahlt sich dieser Audit-Trail aus. Damit ist auch die Compliance-Seite sauber abgedeckt.
Sechs Stolpersteine, die mich am Montagabend zwei Stunden gekostet haben
Live-Entwicklung klingt cool. Gleichzeitig ist sie aber anstrengender, als sie aussieht. Nach dem ersten Tag hatte ich zwar einen Architekturentwurf, allerdings noch keinen durchgehenden Durchstich. Deshalb habe ich mich am Montagabend nochmal zwei bis drei Stunden hingesetzt. Sonst hätte ich am Dienstagmorgen kein gutes Gefühl gehabt.
Die folgenden sechs Punkte sind übertragbar auf jede Pipeline, in der eingehende HR-Mails verarbeitet werden, Sprachmodelle aufgerufen werden, Dokumente generiert werden und mehrere Systeme miteinander reden.
1. Persistenz ist kein Feature, das man am Schluss draufsetzt
Ich habe drei Lösungen probiert, wo ich die Vorgangsdaten zwischenparke. Erst im Workflow selbst, dann in einer Datei, am Ende in einer richtigen Datenbank. Dennoch war jede Iteration besser als die vorige. Allerdings hätte ich mir die ersten beiden sparen können, wenn ich am Anfang fünf Minuten länger über State-Management nachgedacht hätte.
2. Outlook gibt nur die ersten 255 Zeichen einer Mail zurück
Der Microsoft-Standardweg liefert über das Standard-Trigger-Feld nur einen abgeschnittenen Mail-Body. Bei einer kurzen Mail merkt man das zunächst nicht. Bei einer ausführlichen HR-Anfrage gehen genau die wichtigsten Details verloren. Die Lösung: ein zusätzlicher Graph-API-Call, der die vollständige Mail nachholt. Dieser Workaround hat mich am Montagabend zwei Stunden gekostet.
3. Eine Shared Mailbox ist keine normale Mailbox
Die Adresse onboarding@... ist eine geteilte Mailbox. Folglich funktionieren manche OAuth-Standardabfragen nicht wie erwartet. Wir mussten den Auth-Pfad anders bauen, damit der Workflow die Mails überhaupt lesen darf. Edge-Cases im Setup sind teurer als im Code, denn sie zeigen sich erst dann, wenn der Workflow eigentlich schon stehen sollte.
4. Die KI macht aus jedem Berufsbild irgendetwas
Wenn jemand eine Rolle eingibt, die nicht zu den fünf Berufsgruppen gehört, mappt Claude sie automatisch auf die nächstbeste. Das ist gleichzeitig Feature und Bug. Für die Demo nützlich, denn das System kapituliert nicht. Für den Produktivbetrieb wichtig zu wissen, denn bei einer „IT-Admin“-Rolle entsteht ein Plan für eine Sachbearbeiterin. Folglich braucht es entweder eine harte Validierungsschicht oder eine offen kommunizierte Annahme im Plan selbst.
5. Daten gehen zwischen Systemen verloren, wenn man sie nicht aktiv durchreicht
Mittendrin im Ablauf waren plötzlich alle Informationen weg. Zwei Bausteine im n8n-Workflow „bedienten“ das Datenpaket unterschiedlich. Der eine Baustein erwartete ein Array, der andere dagegen ein Objekt. Daher landete am Switch-Node ein leeres Item. Die Lösung war ein zusätzlicher Code-Node, der die Daten an jeder kritischen Station neu zusammenträgt. Defensiv programmieren spart später Stunden.
6. Live-Tests am echten System schlagen jede Theorie
Ich habe am Montag und Dienstag mindestens vierzig Test-Mails geschickt. In jeder zweiten Runde habe ich übrigens einen kleinen Fehler gefunden, den ich vorher nicht gesehen hatte. Schließlich zeigt sich erst beim echten Durchlauf, ob die Bausteine zusammenpassen. Demos sind kein letzter Schritt. Sie sind also der eigentliche Test.
Die Live-Demo: drei Test Cases, ein Plenum
Am Dienstag um 13 Uhr stand ich vor dem Plenum. Dabei lief das System parallel im Hintergrund. Ich hatte drei Test Cases vorbereitet, die nacheinander durchliefen.
Im ersten Fall ging eine vollständige HR-Mail an die geteilte Mailbox. Eintrittsdatum, Rolle, Vorgesetzter, Abteilung waren alle drin. Nach 90 Sekunden kam die Antwort mit allen drei Formaten im Anhang. Word öffnete sich sauber, Excel zeigte die filterbare Phasen-Tabelle, das PDF war druckfertig.
Im zweiten Fall hatte die Mail absichtlich keine Eintrittsdaten. Das System reagierte wie geplant: höfliche Rückfrage zurück, Vorgangs-ID im Betreff, eine Liste der fehlenden Pflichtangaben. Ich antwortete live aus der Demo heraus, der Status sprang auf COMPLETE, der Plan kam.
Im dritten Fall haben meine beiden Paten aus dem Open Space selbst eine Test-Mail geschickt. Mit Fantasiedaten und absichtlich unvollständig. Das System extrahierte die vorhandenen Pflichtdaten, fragte die fehlenden höflich nach, und nach der Antwort kam der fertige Plan zurück. Beide Paten waren mit dem Handling sichtbar zufrieden. Genau das war der Moment, in dem aus einem Prototyp ein nutzbares Werkzeug wurde.
Alle drei Test Cases liefen sauber durch. Das Publikum war sichtbar überrascht. Außerdem ist die Reaktion typisch: Die meisten staunen darüber, wie nah dran ein Prototyp schon ist, ohne Großprojekt-Dimensionen zu haben. Ein einzelner Mensch, zwei halbe Tage, plus die Abendsession am Montag.
Den Onboarding-Prozess automatisieren: was das für eure Organisation heißt
Wer heute den Onboarding-Prozess automatisieren will, kann das mit überschaubarem Mitteleinsatz tun. Vor zwei Jahren hätte derselbe Use Case vier bis sechs Wochen Entwicklungszeit gekostet. Außerdem ein Team aus Fachleuten. Heute reicht ein Mensch mit Workflow-Tool, ein Sprachmodell und ein klarer Kopf für die Anforderungen, die wirklich gebraucht werden.
Die zentrale Erkenntnis aus dem Open Space ist nicht technisch. Sie ist vor allem organisatorisch: Lauffähig schlägt perfekt. Wer dagegen auf den großen Wurf wartet, baut nichts. Wer früh einen Prototyp am echten System testet, sieht innerhalb weniger Tage, wo die echten Stolpersteine liegen. Genau dort, wo der Use Case auf die Realität trifft. Nicht in der Architektur-Skizze.
Wenn ihr in eurer Organisation eine HR-, Vertrags- oder Antrags-Routine habt, von der ihr ahnt, dass sie zu viel Zeit kostet, aber zu klein für ein Software-Projekt wirkt: schreibt mich an. Denn genau dafür sind solche Prototypen gedacht. Damit ihr seht, wie viel mit wenig Aufwand möglich ist, bevor ihr große Entscheidungen trefft. Ich baue das Pendant für euren Use Case.
Mehr Beispiele aus echten n8n-Workflows findet ihr außerdem in meinem Bericht zum YouTube-Zusammenfassungs-Workflow mit Whisper und Ollama. Insbesondere dort steht die gleiche Logik im Vordergrund: schnell sichtbar machen, dann iterativ verbessern. Übrigens nach demselben Muster, das jetzt den Onboarding-Prozess automatisieren kann.