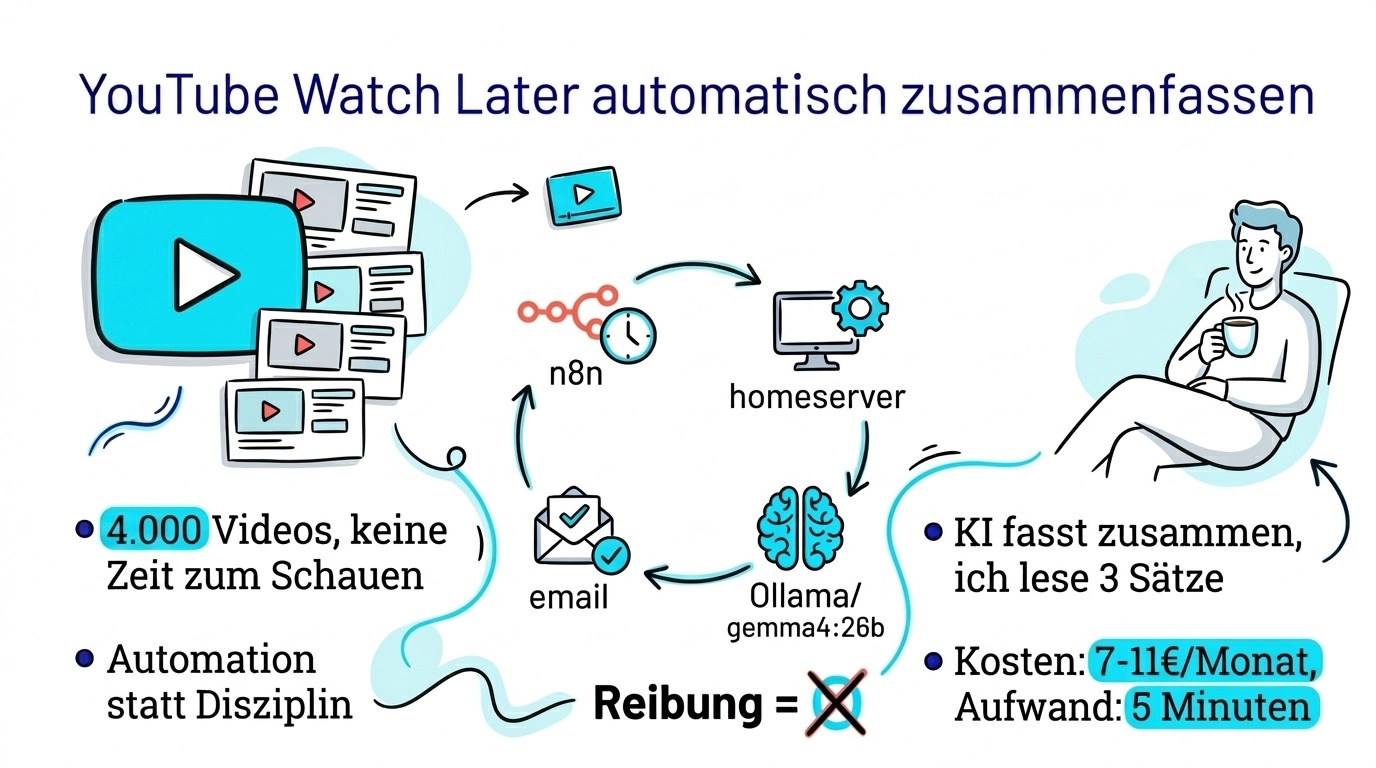
YouTube Watch Later automatisch zusammenfassen — das klingt nach einem Nischenproblem, ist aber für mich zur echten Produktivitätslösung geworden. Meine Playlist hatte sich auf über 4.000 Videos angesammelt. Guter Inhalt, den ich nie angeschaut habe. Also habe ich das Problem anders gelöst.
Das eigentliche Problem: Watch Later als Schuldgefühl-Liste
Ich vermute, du kennst das. Ein Video landet in Watch Later, weil der Titel interessant klingt. Dann kommt das nächste. Und das übernächste. Irgendwann ist die Playlist ein Friedhof guter Absichten.
Das Problem ist nicht Faulheit. Das Problem ist die Lücke zwischen „ich will das schauen“ und „ich habe gerade 45 Minuten Zeit für genau dieses Video“. Diese Lücke schließt sich selten.
Meine Lösung: Ich schaue die Videos nicht mehr. Meine KI macht das für mich — und schickt mir bei neuen Videos eine E-Mail mit den wichtigsten Erkenntnissen. So kann ich selbst entscheiden, ob ich die Infos aus einem Video wirklich brauche, ohne es komplett schauen zu müssen.
Gerade im Bereich KI ist das entscheidend: Nichts ist so schnell und aktuell wie YouTube-Videos. Klassische Weiterbildungen sind in diesem Tempo oft schon veraltet, bevor sie abgeschlossen sind. Um wirklich am Ball zu bleiben, muss ich die aktuellsten Informationen konsumieren — und das geht nur, wenn die Reibung im Prozess gegen null geht.
Wie der Workflow funktioniert
Der Workflow läuft stündlich auf n8n, das ich selbst auf Hostinger hoste. Er besteht aus 24 Nodes und kostet mich rund 7 Euro im Monat für den Hostinger-Server sowie 1–4 Euro Strom für den Mac Mini, abhängig von der Auslastung.
Der Ablauf ist geradlinig:
- 🔁 n8n prüft stündlich die YouTube-API auf neue Videos in meiner „Zu analysieren“-Playlist
- 📅 Ein Datumsfilter sortiert alles heraus, was älter als 5 Tage ist
- ✅ Eine Deduplizierungsprüfung gegen eine n8n Data Table stellt sicher, dass kein Video zweimal verarbeitet wird
- 🔢 Ein Batch-Limit sorgt dafür, dass pro Durchlauf maximal 9 Videos verarbeitet werden
- 📄 Das Transkript des Videos wird über einen eigenen Service auf meinem Homeserver abgerufen
- 🤖 Das Transkript (max. 15.000 Zeichen) geht an gemma4:26b via Ollama
- 📩 Die Ergebnisse aller Videos aggregiert n8n zu einer formatierten HTML-E-Mail, die nur dann über Gmail verschickt wird, wenn tatsächlich neue Videos vorliegen
Das Ergebnis: Eine E-Mail mit Thumbnail, Titel, Kanal, einem 2-3-Sätze-Summary und den Top 10 Learnings pro Video. Ich scanne das in 5 Minuten beim Kaffee.
Der Tech Stack — und warum ich ihn so gewählt habe
Jede Komponente hat einen konkreten Grund, warum sie hier ist.
n8n als Orchestrator
n8n ist mein bevorzugtes Automatisierungswerkzeug, seit ich es für andere Workflows ausprobiert habe — darunter auch meinen KI-gestützten Diktat-Workflow mit Whisper. Es ist selbst gehostet, Open Source, und die visuelle Node-Struktur macht Debugging deutlich einfacher als Code. 24 Nodes klingen nach viel — sind aber überschaubar, wenn jeder Node genau eine Aufgabe hat.
YouTube-API und Homeserver-Service für die Transkripte
Die YouTube Data API v3 nutze ich ausschließlich, um die Playlist-Items abzufragen: Titel, Video-IDs und Thumbnails. Die Transkripte liefert sie nicht — das übernimmt ein eigener Service, der auf meinem Homeserver läuft und über Tailscale erreichbar ist. n8n ruft diesen Service per HTTP-Request ab, er gibt das Transkript als Text zurück. Das hält die Architektur sauber: Die offizielle API bleibt für Metadaten zuständig, der Homeserver-Service für den eigentlichen Transkript-Abruf.
gemma4:26b via Ollama — und warum ich gewechselt habe
Ich habe den Workflow ursprünglich mit ministral gestartet. Das Modell hat funktioniert, war aber langsam und die Zusammenfassungsqualität war durchwachsen. Der Wechsel auf gemma4:26b hat zwei Dinge gleichzeitig verbessert: doppelte Geschwindigkeit und deutlich bessere Qualität bei den Learnings.
Das Modell wiegt 18 GB und läuft komplett im Unified Memory des Mac Mini (Apple Silicon). Ollama macht die Verwaltung und den API-Zugriff einfach — ein Befehl, und das Modell läuft als lokaler Endpunkt. 60 Token pro Sekunde sind das Ergebnis. Das ist schneller als viele Cloud-APIs, die ich kenne.
Daher lohnt es sich, Apple Silicon als KI-Inference-Plattform nicht zu unterschätzen. M-Chips haben einen riesigen gemeinsamen RAM-Pool für CPU und GPU — das ist genau das, was lokale Sprachmodelle brauchen.
Tailscale als Netzwerk-Kleber
n8n läuft auf einem Hostinger-Server irgendwo in der Cloud. Der Mac Mini steht bei mir zu Hause. Tailscale verbindet beide über ein privates Mesh-Netzwerk — ohne Port-Forwarding, ohne VPN-Konfiguration, ohne offene Ports nach außen. Der Workflow-Server erreicht den Homeserver einfach über eine stabile Tailscale-IP — sowohl für den Ollama-Endpunkt als auch für den Transkript-Service.
Der KI-Prompt — schlicht und effektiv
Der Prompt, den jedes Video bekommt, ist bewusst einfach gehalten:
Du bist ein Assistent, der YouTube-Video-Transkripte analysiert.
Video-Titel: [Titel]
Kanal: [Kanal]
Transkript:
[Bis zu 15.000 Zeichen]
---
ZUSAMMENFASSUNG:
[2-3 Sätze die erklären worum es im Video geht]
TOP 10 LEARNINGS:
1. bis 10.Temperature 0.3, max. 1.024 Tokens, Thinking-Mode deaktiviert. Die niedrige Temperature sorgt für konsistente, faktennahe Ausgaben — kein kreatives Ausschmücken, das bei Lernzusammenfassungen eher stört als hilft. Der deaktivierte Thinking-Mode bei gemma4 spart Zeit, weil das Modell keine internen Überlegungsschritte durchläuft, die ich sowieso nicht sehe.
Ich habe kontinuierliches Lernen schon immer als wichtig eingestuft — dieser Workflow macht es jedoch systemisch. Die KI lernt nicht für mich, aber sie beseitigt die Reibung, die mich davon abhält, überhaupt anzufangen.
Performance und Kosten — die ehrlichen Zahlen
Pro Video brauche ich rund 15 Sekunden Gesamtdurchlaufzeit: Transkript-Abruf über den Homeserver-Service plus 5-10 Sekunden gemma4-Analyse. Für einen asynchronen Hintergrundprozess ist das absolut ausreichend.
Die laufenden Kosten: rund 8–11 Euro im Monat. Das setzt sich zusammen aus ca. 7 Euro für den Hostinger-Server und 1–4 Euro Strom für den Mac Mini, der ohnehin als Homeserver läuft. Kein OpenAI-Token, keine Google-Cloud-API, kein Anthropic-Abo. Das Modell ist Open Source, n8n ist selbst gehostet, Ollama ist kostenlos.
Zum Vergleich: Würde ich für jedes Video die OpenAI API nutzen (GPT-4o, ~15.000 Zeichen Input), kämen schnell 2-5 Cent pro Video zusammen. Bei 50 Videos im Monat sind das 1-2,50 Euro — klingt wenig, aber skaliert bei intensiverer Nutzung. Und ich habe keinen Datenschutz-Overhead, weil nichts meine Infrastruktur verlässt.
Was dieser Workflow wirklich verändert
Der eigentliche Shift ist nicht technischer Natur. Es geht darum, wie ich mit Information umgehe.
Früher war Watch Later eine passive Sammlung. Jetzt ist es eine aktive Inbox, die stündlich verarbeitet wird — nicht von mir, sondern vom System. Ich bekomme die Essenz, entscheide dann, ob ich das vollständige Video wirklich sehen will, und spare mir in den meisten Fällen 20-40 Minuten pro Video.
Das ist besonders im Bereich KI entscheidend. Klassische Weiterbildungen sind in diesem Feld oft schon überholt, bevor sie abgeschlossen sind. YouTube-Videos sind dagegen das schnellste Medium, um mit dem aktuellen Stand mitzuhalten. Dieser Workflow stellt sicher, dass ich keine relevante Information verpasse — ohne täglich Stunden vor dem Bildschirm zu verbringen.
Das verändert auch, was ich in die Playlist aufnehme. Weil ich weiß, dass jedes Video verarbeitet wird, ist der Filter beim Hinzufügen lockerer geworden. Ich speichere mehr. Gleichzeitig konsumiere ich selektiver, weil ich aus der E-Mail schnell erkenne, welche Videos wirklich relevant sind.
Außerdem ist das Modell-Upgrade von ministral auf gemma4 ein konkretes Beispiel dafür, wie lokale KI sich weiterentwickelt. Vor einem Jahr hätte ich für diese Qualität zwingend Cloud-APIs gebraucht. Das stimmt heute nicht mehr. Die Open-Source-Modelle schließen die Lücke schneller als erwartet — auch auf Consumer-Hardware.
Was du brauchst, wenn du das nachbauen willst
Du brauchst keinen eigenen Server oder Mac Mini, um dieses Konzept auszuprobieren. Allerdings: Je mehr du auf eigene Hardware setzt, desto mehr Kontrolle und Kosteneinsparung bekommst du.
Für eine erste Version reicht folgendes:
- 🖥️ n8n (selbst gehostet oder n8n Cloud für Tests)
- 🔑 YouTube Data API v3 (kostenlos, braucht Google-Entwicklerkonto) — für Playlist-Metadaten
- 📄 Ein Transkript-Service (z. B. ein kleines Python-Skript mit youtube-transcript-api) auf einem erreichbaren Server
- 🤖 Ollama mit einem kleineren Modell (llama3.2:3b läuft auch auf normalen Rechnern)
- 📧 Gmail oder ein anderer SMTP-Dienst für den Versand
Der aufwendigste Teil ist das Netzwerk-Setup, wenn Cloud-Server und Homeserver kommunizieren sollen. Tailscale löst das in unter 10 Minuten — und ist für den persönlichen Einsatz kostenlos.
Wer den Einstieg in Automatisierung mit n8n sucht, findet auf der offiziellen n8n-Dokumentation gute Startpunkte. Die Community ist aktiv und hat für die meisten Integrationen bereits fertige Templates.
Der Workflow als lebendiges System
Der Workflow ist kein abgeschlossenes Produkt. Er erfüllt genau das, was ich brauche — und wenn neue Anforderungen dazukommen, passe ich ihn entsprechend an. Genau so sollte Automatisierung funktionieren: pragmatisch, nicht perfekt.
Wenn du ähnliche Workflows baust oder Fragen zur Architektur hast — schreib mir. Ich teile gerne mehr Details zur Node-Konfiguration oder zum Setup auf dem Mac Mini.